21. Yüzyılda Avusturya’daki Sözcük Çeşitliliği Atlası Projesi
(LexAT21 – Atlas on lexical variation in Austria in the 21st century)
Proje Linki: https://lexat21.lapis-online.at/en
Suna Sever
1. Projenin Amacı ve Kuramsal Çerçevesi
LexAT21 projesi, dijital beşeri bilimler yöntemlerini uygulayarak Avusturya’daki çağdaş Almancanın kelime çeşitliliğini tespit etme ve belgelemeyi amaçlayan bir bir dil atlası ve dil bilim projesidir. Merkezinde; bölgesel ağızlar, günlük konuşma dili ve standart Almancaya dair çeşitli veriler yer almaktadır. Bu proje, sözcük çeşitliliğinin sistematik bir şekilde belgelenmesine yönelik etkileşimli leksik atlas oluşturma, dilin coğrafi ve sosyo demografik sınırlarını belgeleme amacıyla yürütülmektedir. LexAT21 projesi, tek başına bir proje olmaktan ziyade, Avusturya Almancasının varyasyonunu, temasını ve algısını inceleyen daha geniş ölçekli ve uzun soluklu bir araştırma programını bünyesinde barındırmaktadır. Atlasın yeni anketlerle güncellenmesi, verilerin akademik yayınlarla derinlemesine analiz edilmesi ve ulusal/uluslararası dil bilimsel projelerle bağlantılı veri (Linked Data) standartlarında entegrasyonu hedeflenmektedir. Temmuz 2021’de başlayan projenin I. turu Mayıs 2023'te tamamlanmış olup 46 olgunun analizi raporlanmıştır. Proje, 2016-2026 yıllarını kapsayan ana program (SFB DiÖ) ile uyumlu olarak II. ve III. tur çalışmalarıyla gelişimini sürdürmektedir.
Bu proje, bölgesel ağızlardaki sınırların güncel durumunu ve günlük konuşma dili, standart Almanca kullanımlarına yönelik sosyo demografik faktörlerin etkilerini ve dağılımlarını konu alan sorulara cevap aramaktadır. Çevrimiçi anketlerle toplanan dil verileri, etkileşimli haritalama araçları, tematik haritalar ve sosyodemografik analiz grafikleriyle kullanıma sunulmakta, böylece katılımcılara kendi kelime dağarcıklarını belgeleme fırsatı vermektedir.
LexAT21’in ayrı veya bağımsız bir bütçesi, arama sonuçlarından net bir şekilde çıkarılamamaktadır. Ancak projenin finansal büyüklüğü, entegre olduğu SFB programının ölçeği üzerinden tahmin edilebilmektedir. Bütçe, FWF’in SFB DiÖ (F 060) programı kapsamındaki ana bütçeden sağlanmaktadır. Bu tür özel araştırma programları genellikle yıllık yaklaşık 1.000.000 Avro bütçeye sahip olan ve sekiz yıl süren uluslararası standarttaki ağlardır.
2. Uygulama Süreci ve İçerik Yapısı
LexAT21 projesini dil bilimi ve bilgisayar destekli dil bilim (Computational Linguistics) alanlarında uzman olan bir ekip yönetmekte ve geliştirmektedir. Projenin baş editörlüğünü ve sorumlu yöneticiliğini Viyana Üniversitesi’nden tanınmış bir dil bilimci olan Prof. Dr. Alexandra N. LENZ yürütmektedir. LexAT21’in çevrimiçi altyapısı ve haritalama aracını Jakob BAL, Kilian KUKELKA, Markus PLUSCHKOVITS, Daniel SCHOPPER ve Anja WITTIBSCHLAGER geliştirmektedir. Ayrıca atlasın bilimsel içeriğini hazırlama, anket verilerini görselleştirme ve verileri erişilebilir duruma getirme noktasında teknik web uygulaması da bu ekip tarafından hazırlanmıştır. Projenin yazarları; Amelie DORN, Jan HÖLL, Wolfgang KOPPENSTEİNER, Katharina KORECKY-KRÖLL, Alexandra N. LENZ, Claudia MATTES, Markus PLUSCHKOVİTS, Rita STİGLBAUER, Florian TAVERNİER, Anja WİTTİBSCHLAGER, Theresa ZİEGLER’dir. Düzeltmenlik görevi, Kerstin LORENZ, Eric SCHİRL tarafından yapılmaktadır. Özetle LexAT21 projesi, Viyana Üniversitesi (Universität Wien) merkezli olmak üzere Avusturya’daki dil bilim araştırmalarının önemli bir parçası olarak yürütülüyor.
Projenin ana sponsorluğu ve araştırmaların temelinin finanse edilmesi FWF (Fonds zur Förderung der wissenschaftlichen Forschung / Avusturya Bilim Fonu) tarafından sağlanıyor. Projenin diğer iş birlikçileri aynı zamanda FWF tarafından finanse edilen büyük ölçekli bir araştırma programı olan SFB "Deutsch in Österreich, Variation – Kontakt – Perzeption" (Kısaltma: DiÖ - F 060) –Avusturya’da Almanca, Varyasyon – Temas – Algı- (Spezialforschungsbereich Deutsch in Österreich: Variation - Kontakt - Perzeption ) ile 2024 yılının Ocak ayından itibaren Viyana Üniversitesi bünyesindeki ACDH (Austrian Centre for Digital Humanities / https://www.oeaw.ac.at/acdh/acdh-home Dil bilim Araştırma Departmanı ve SFB DiÖ’dir. Bu işbirlikleri LexAT21 projesinin genişletilmesi, projenin kurumsal ve teknik entegrasyonunu desteklemektedir.
2021 yılının Temmuz ayında başlayan proje, tarihî ağızlardan ziyade yaşayan ve güncel Avusturya Almancasına odaklanarak güncel veri girişleriyle devam etmektedir. Coğrafi kapsamı 9 federal eyaletiyle tüm Avusturya’yı içine alacak şekilde sınırlandırılmıştır. İlk turda kırsal ve kentsel alanları kapsayan 506 farklı noktadan veri sağlanmış, en yoğun katılım ise Viyana'dan gerçekleşmiştir. Projenin ana kaynağı, kitle kaynak (Crowdsourcing) yöntemiyle Avusturya genelindeki gönüllü katılımcıların çevrim içi anketlere verdikleri yanıtlarla oluşturulan dil verileridir. Harita açıklamaları ve bilimsel analizler, Österreichisches Wörterbuch, Duden – Österreichisches Deutsch ve Variantenwörterbuch des Deutschen adlı sözlükler, Avusturya diyalekt söz varlığı için Wörterbuch der historischen bairischen Dialekte in Österreich (WBÖ) ve LIÖ platformu referanslarına dayanmaktadır. 80 yıllık değişimi izlemek için Deutscher Wortatlas (DWA) ve güncel yerel dil kullanımı için Atlas zur deutschen Alltagssprache (AdA) temel karşılaştırma referanslarıdır.
Katılımcılara ulaşmak için üniversite e-posta listeleri, sosyal medya ve bilimsel toplulukların yanı sıra "kartopu metodu" (katılımcıların anketi kendi çevrelerine iletmesi) kullanılmaktadır. Veri toplama belirli aylara yayılan turlar halinde planlanmakta ve anket sayısı 1.900’e ulaştığında ilgili tur sona erdirilmektedir. Bir anketin veri seti olarak kabul edilmesi için tamamen doldurulmuş olması ve Avusturya sınırları içerisinde geçerli bir yer belirtilmesi şarttır. Örneğin, birinci turdaki 2080 anketten sadece 1925’i bu şartları sağladığı için analize dahil edilmiştir. Anketlerin ağırlıklı olarak üniversiteler üzerinden duyurulması nedeniyle örneklemde öğrenci sayısı ortalamanın üzerindedir. Örneğin I. Turda Katılımcıların %32'si öğrencidir ve 30 yaş altı kadın öğrenciler lehine bir yoğunluk söz konusudur. II. Tur ise ilk tura oranla katılımcı dağılımı demografik açıdan daha dengeli bir görünüm sergilemektedir.


Görsel 1 & 2: I. Tur Katılımcılarının Genel Sosyodemografik Özellikleri
I. tur verilerinde kadın katılımcı sayısının erkeklere oranla daha fazla olduğu ve verilerin eğitimli, genç-orta yaş grubundaki kadınların dil kullanımını yansıttığı görülmektedir. Katılımcıların ortalama yaşı 39 olup çoğunluğunu öğrenciler oluşturmaktadır; 30-50 yaş grubu (1.371 kişi), 50 üstü yaş grubunun (554 kişi) yaklaşık iki buçuk katıdır. Proje, bireylerin diyalekt-standart dil eksenindeki iç varyasyonuna odaklanarak söz varlığı değişimlerini hem kuşaklar arası (eşzamanlı) hem de uzun dönemli olarak incelemektedir. İlk turda, 1950–1980 yılları arasındaki diyalekt atlasında yer alan 46 olgu yeniden ele alınarak yaklaşık 85 yıllık bir değişim karşılaştırması yapılmıştır. Her dilsel değişken, en sık kullanılan 2–3 kelime varyantı (örneğin; burarak sıkmak için kullanılan farklı kelimeler) ile adlandırılmakta ve haritalandırılmaktadır. Kelimelerdeki ince telaffuz ve biçim farklılıkları, veri tabanındaki yazım varyantları üzerinden ayrıntılı bir şekilde analiz edilebilmektedir.

Görsel 3: Veri çeşitliliği ve Miktarı
3. Yöntem ve Dijital Altyapı
Proje, temelinde Dijital Beşeri Bilimler yöntemlerini barındırır ve verilerini açık kaynaklı LimeSurvey yazılımı üzerinden yapılan kapsamlı çevrimiçi anketlerle toplar. Katılımcıların standart Avusturya Almancası, ağız (Dialekt) ve günlük konuşma dili (Regiolekt) kapsamındaki bireysel söz dağarcıkları ve kelime kullanımları sorgulanmaktadır. Toplanan veriler Baserow uygulaması ile işlenir; leksikal kategorilendirmeler proje ekibi tarafından manuel olarak yapılırken orijinal veriler şeffaflık için muhafaza edilmektedir. Temizlenen ve etiketlenen veriler, PostgreSQL tabanlı ilişkisel bir veritabanına aktarılır ve Austrian Centre for Digital Humanities and Cultural Heritage tarafından barındırılır. Arka uç Hono-framework ile geliştirilmiştir; haritalama ve görselleştirmeler için MapLibre ve three.js teknolojileri kullanılmaktadır. Projenin teknik mimarisi ve veri modeli LAPIS ve LIÖ platformlarına dayanarak dil verileri arasında birlikte çalışabilirliği amaçlar; ilerleyen süreçte OpenAPI arayüzü ile dış erişim planlanmaktadır.
Veri Erişimi, "Örnek veri tabanı" üzerinden projenin orijinal verilerine ve bu verilerin sözlüksel varyant sınıflarına göre kategorize edilmiş hâllerine doğrudan erişim imkânıyla sunulmaktadır. Haritalama aracında kullanılan tüm görselleştirmeler, veri tabanındaki bu sistematik sınıflandırmalara dayanmaktadır. Kullanıcılar; olgulara, kayıt türlerine, varyantlara ve katılımcıların yaş gruplarına göre kapsamlı filtreleme yaparak veriler üzerinde derinlemesine analiz yapabilmektedir. Platform, analiz sürecini kolaylaştırmak amacıyla verilerin kullanıcılar tarafından indirilebilmesine olanak sağlamaktadır.
Toplanan geniş kapsamlı dil verilerini anlamlandırmak için geliştirilen haritalama aracı, verileri bireysel biçimde görselleştirme ve haritalama imkânı sunmaktadır. Kullanıcılar; katılımcı yaş grupları ve dil varyantları gibi kriterlerle sunumu kişiselleştirebilmekte, ayrıca kendi renk şemalarını tanımlayabilmektedir. Hazırlanan haritalar, sunum ve analizlerde kullanılmak üzere yüksek çözünürlüklü görüntü formatlarında dışa aktarılabilmektedir. Harita açıklamaları, dil coğrafyası bulgularına odaklanarak dil kullanımını standart Almanca - Hochdeutsch, günlük konuşma dili - Umgangssprache ve ağız - Dialekt gibi üç farklı düzeyde inceleme olanağı sağlamaktadır. Yazılı açıklamalar, değişkenin tanımını içeren kısa açıklamalar ve varyasyonları analiz eden yorumlayıcı uzun açıklamalar olmak üzere iki ana türe ayrılabilmektedir. Görselleştirme için kullanılan renk sistemi ise varyantların sıklığına göre kodlanmış olup en sık görülen varyant koyu kırmızı, ikinci en sık görülen varyant mavi tonları, diğer muhtemel varyantlar için de yeşil ve sarı renklere yer verilmektedir. Bu sistemle dil haritası üzerindeki bilgilerin sistematik ve anlaşılır bir biçimde sunulması amaçlanmaktadır.

Görsel 4: Örnek veri tanımlaması ve analizi
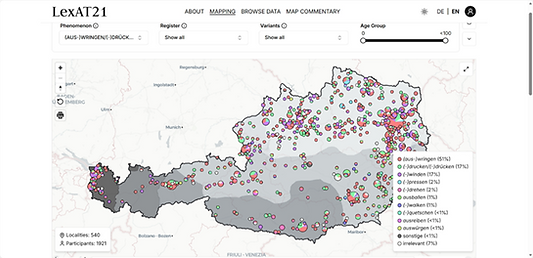
Görsel 5: Veri sıklık dağılımına yönelik bir örnek.
Proje, Açık Erişim (Open Access) ilkeleri doğrultusunda leksikal atlası ve bilimsel bulguları ücretsiz olarak halka sunmaktadır. Katılımcı adresleri ve bireysel yorumlar gibi ham veriler gizlilik gereği paylaşılmaz; bunun yerine anonimleştirilmiş grafikler, haritalar ve istatistiksel veriler erişime açılır. Verilerin korunması ve anonimleştirilmesi ilkeleri Viyana Üniversitesi ve sponsor sayfalarında belirtilmiş olup; anketler gönüllülük esasına ve kişisel bilgilerin gizliliğine dayanmaktadır. Veriler, Viyana Üniversitesi ve ACDH sunucularında, FWF destekli projelerin titiz veri yönetimi protokolleri uygulanarak güvenli bir şekilde depolanmaktadır. Katılımcılara ulaşmak için üniversite e-posta listeleri, bilimsel topluluklar ve alt yerleşim birimleri kullanılırken, SFB DiÖ programının sosyal medya hesaplarından da faydalanılmaktadır. LexAT21, metodolojik olarak günlük konuşma dilini haritalayan Atlas zur deutschen Alltagssprache (AdA) ve Avusturya ağızlarının veri tabanını oluşturan eDDA gibi dijital dil atlası projeleriyle benzerlik ve tamamlayıcılık ilişkisi içindedir.
4. Çıktılar, Katkılar ve Gelecek Perspektifi
Proje kapsamında yapılan yayınlar, projenin bilimsel danışmanlığını yürüten Prof. Dr. Alexandra N. Lenz ve ekip üyelerinin katkılarıyla web-yayını şeklinde hazırlanmaktadır. Projenin tanıtımı, metodolojisi, verileri ve bulguları hakkındaki analizlerin detaylandırıldığı proje web-yayınlarına ilişkin temel çıktı, interaktif bir web tabanlı kaynak olan atlasın kendisidir. Bu atlasta yer alan proje bilgilerinin yanı sıra veri datalarını oluşturan sözcüklerin anlam ve varyantlarını içeren yazılar da yine projenin çekirdek araştırma ekibi tarafından yazılmaktadır:
LENZ, Alexandra N. (2025). LexAT21 – Ein Lexikatlas und seine Hintergründe , In: LexAT21: Atlas zur lexikalischen Variation in Österreich im 21. Jahrhundert. [URL: https://lexat21.lapis-online.at/de/articles/lexat21-einfuehrung].
Projeyle ilgili tanıtımlar, projeyi destekleyen kurumların (Viyana Üniversitesi, ACDH (Austrian Centre for Digital Humanities / Avusturya Dijital Beşeri Bilimler Merkezi) ve ÖAW (Austrian Academy of Sciences / Avusturya Bilimler Akademisi)’in kurumsal web sayfalarında yer almaktadır:
Projenin tanıtımı çeşitli konferanslarda bildiri olarak da sunulmuştur. Aşağıda verilen kaynakta bildirinin slayt sunumuna dair bağlantı paylaşılmıştır: Markus PLUSCHKOVİTS, Daniel SCHOPPER, Anja WİTTİBSCHLAGER, Jakob BAL and Kilian KUKELKA. A resource for lexical variation in a pluri-areal context: Introducing LexAT21, the atlas on lexis in Austria in the 21st century. [Konferans sunumu]. International Conference on Dialectology and Sociolinguistics, Salzburg, Avusturya. (slides).
Aşağıdaki çalışma ise LexAT21 projesi gibi varyasyon araştırmalarındaki verileri ve yöntemleri, dijitalleştirilmiş dil bilimsel veri setlerinin kalitesi ve gerekli temel teknik altyapı konularını, Avusturya Almancası üzerinden ele alan metodolojik bir çalışmadır: PLUSCHKOVİTS, M. (2023). Annotating German in Austria: A case-study of manual annotation in and for digital variationist linguistics. Journal of Digital Linguistics, 11(2), 145–160.
https://dhq.digitalhumanities.org/vol/17/3/000729/000729.html
Görsel olarak sorgulanan leksik değişkenlerin (46 Adet) Avusturya’daki dağılımını gösteren etkileşimli ve tematik sözcük haritaları üretilmiştir.
Bunların yanı sıra katılımcıları yaş, cinsiyet ve coğrafi özelliklerini özetleyen sosyodemografik grafikler kapsamında pasta ve çubuk grafikler üretilmiştir.
Örnek Çıktı Grafikleri






Projedeki temel faaliyet alanları, kapsamlı çevrimiçi anket turları düzenleme, elde edilen verilerin bilimsel analizini yapma, akademik konferanslarda sunumlar yapma ve verilerin görselleştirildiği ve erişime açıldığı dijital atlasın geliştirilmesi ve sürdürülmesine yöneliktir.
Leksikal varyasyonların tutarlı ölçümü için resim veya video dizisi betimleme temelli üretim görevleri kullanılmaktadır. Katılımcılara görsellerdeki nesne/canlı adları ile kişilerin eylemleri sorularak hem isim hem de eylem soylu veriler toplanmaktadır. I. turda, göstergelerin altında ağız (diyalekt), standart dil ve varsa diğer adlandırmalar için üç ayrı yanıt kutusu yer almıştır. II. turda ise birinci turdaki "Diyalekt–Yüksek Almanca" ve "Gündelik Dil–Yüksek Almanca" seçeneklerine ek olarak "Yalnızca Yüksek Almanca" türü eklenmiştir. Anket turlarında ilerleyebilmek için sunulan sorulardan en az birinin yanıtlanmış olması zorunluluğu bulunmaktadır.

Görsel 6: Örnek Anket Soruları
Anket başında "Hochdeutsch" (Standart Almanca); resmi durumlar ve yabancılarla iletişim bağlamında tanımlanırken diyalekt ve gündelik dil, günlük yaşam bağlamıyla ilişkilendirilmektedir. Standart dili ifade eden üç farklı terim kullanılsa da analiz aşamasında tüm bu veriler tek bir "Standart Dil" kategorisinde birleştirilerek haritalandırılmaktadır. Katılımcılardan verilerini Avusturya sınırları içindeki belirli bir yerle ilişkilendirmeleri istenmekte; bu sayede dilsel veriler katılımcıların posta kodları üzerinden haritalandırılmaktadır. Her turda en az 500 civarında yer noktası kullanılmaktadır. Viyana ve Graz gibi büyük şehirler tek bir posta koduyla temsil edilirken; Aşağı Avusturya, Yukarı Avusturya ve Viyana bölgelerinde yoğun bir veri kümelenmesi görülmektedir.

Görsel 7: Sol taraf, “Yer Noktaları (Ortspunkte)” ve
sağ taraf, “Katılımcılar (Teilnehmende)”
LexAT21 sonuçlarını değerlendirirken Wiesinger’in 1983 tarihli klasik ağız ayrımı, temel referans noktası olarak kabul edilmektedir. Toplanan güncel veriler, geleneksel ağız sınırlarının (örneğin Ostmittelbairisch ve Westmittelbairisch ayrımı) hâlâ geçerli olup olmadığını veya modernleşme etkisiyle kaybolup kaybolmadığını test etmek için kullanılmaktadır. Güncel kelime haritaları, geleneksel ağız haritasının üzerine yerleştirilerek sözcük seviyesindeki varyasyonun tarihsel bölgelerle örtüşme ve sapma noktaları görselleştirilmektedir. Modern ulaşım, medya ve eğitim gibi faktörlerin geleneksel dilsel sınırları ne ölçüde ortadan kaldırdığı bu karşılaştırmalı analizle belirlenmektedir.

Görsel 8: Temel Harita (Wiesinger 1983'e Göre Avusturya'daki Ağız Alanları)
4.1. Türkiye Bağlamında Genel Değerlendirme
Doğrudan tarih yazımıyla ilgili olmasa da dil varyasyonları; göç, ticaret, sosyal hareketlilik ve yerel kimliklerin derinlemesine araştırılmasında destekleyici veriler sunmaktadır. Türkiye gibi çok katmanlı bir coğrafyada, her ilde bulunan üniversiteler ve ilgili bölümler aracılığıyla kitle kaynaklı (crowdsourcing) metodoloji kullanımı oldukça elverişli ve işlevsel bir potansiyel taşımaktadır. Benzer bir çalışma; dilsel ve kültürel değişimler, göç hareketleri, medyanın etkisiyle oluşan dilde homojenleşme ve kuşaklar arası dil farklılıkları üzerine geniş çaplı analiz fırsatları sağlayacaktır. Dijital beşeri bilimler uygulamaları, büyük veri setlerinin hızlı ve düşük maliyetle toplanmasını sağlayarak analitik süreci hızlandıracaktır. Etkileşimli dijital atlaslar ve açık erişim sunumu, bilginin kullanımını demokratikleştirirken; bağlantılı veri teknolojileri, tarihî metinler ve veri tabanlarıyla işbirliği kurarak disiplinler arası araştırmaların kapsamını genişletecektir.
Atıf:
Lenz, Alexandra N. (ed.). 2025ff. LexAT21 - Atlas on lexical variation in Austria in the 21st century. Concept and development by Jakob Bal, Kilian Kukelka, Markus Pluschkovits, Marie Rohler, Daniel Schopper und Anja Wittibschlager. With participation from Amelie Dorn, Jan Höll, Katharina Korecky-Kröll, Wolfgang Koppensteiner, Claudia Mattes, Markus Pluschkovits, Rita Stiglbauer, Florian David Tavernier, Anja Wittibschlager, Theresa Ziegler, Kerstin Lorenz and Eric Schirl.